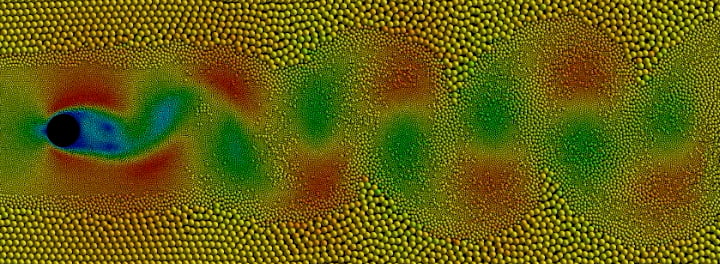
PREON® TECHNOLOGY – IMPLICIT FORMULATION FOR SPH-METHOD
LEADING WITH INNOVATION IN FLUID SIMULATION
We believe that the simulation world is undergoing a similar evolution of performance as the personal computer. And we believe that we are just at the beginning of this evolution. In this endeavor we are playing a key role with our groundbreaking PREON® technology.


