PreonLab
How to develop reliable software (Fast)

Reliability is one of the key drivers of our product development at FIFTY2. Users of PreonLab can always be sure, that new versions have been thoroughly tested before we release them. On the other hand, our quality awareness should not slow us down implementing new features. In this article we show how our development process is structured such that we don’t sacrifice one goal for the other.
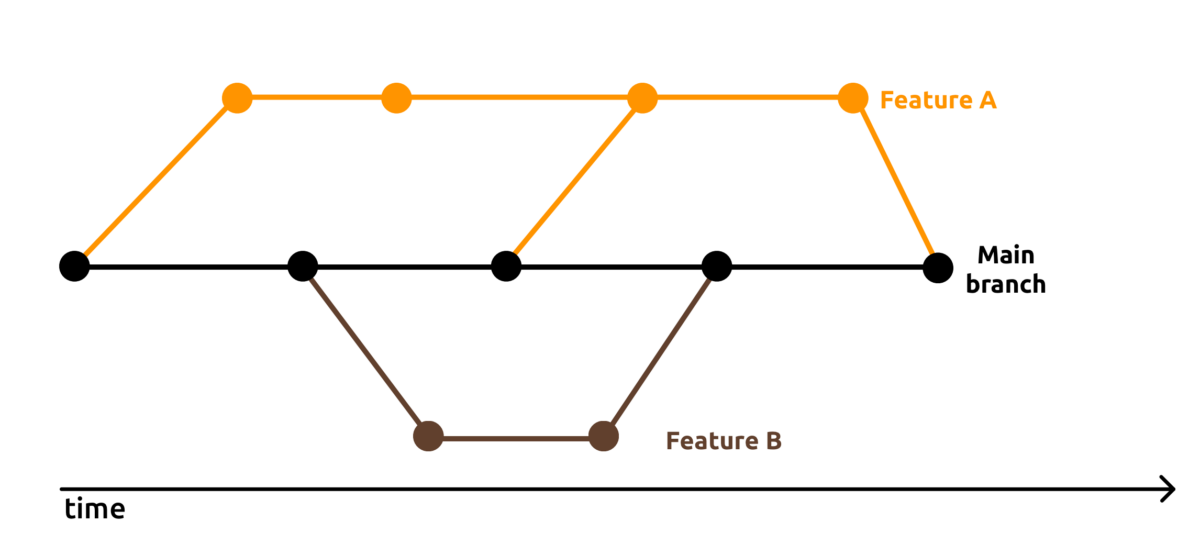
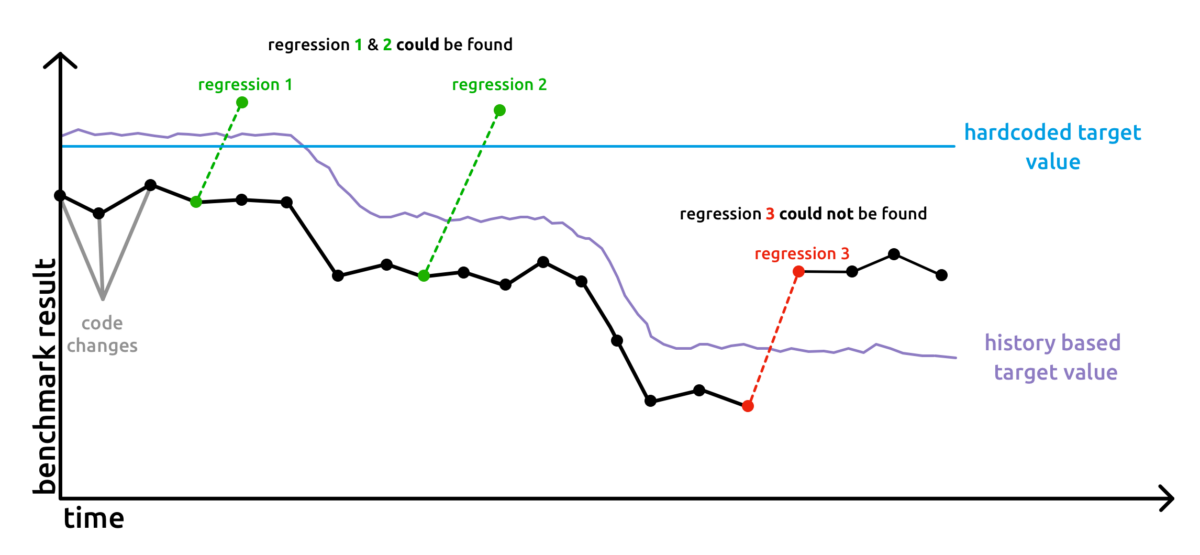
We continuously validate the simulation results and the application behavior. This means, that every new feature is carefully looked at. Our engineering team analyzes the result and validates physical aspects. New development should also not break existing workflows. There are a lot of different aspects of quality assurance, which in combination makes PreonLab an enjoyable user experience.
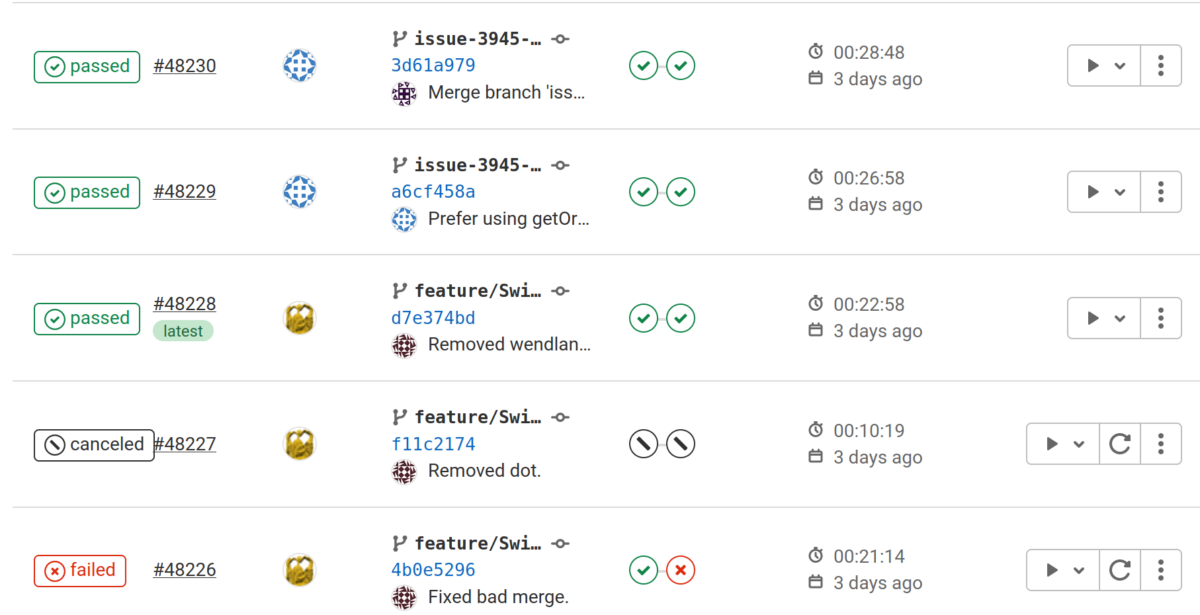
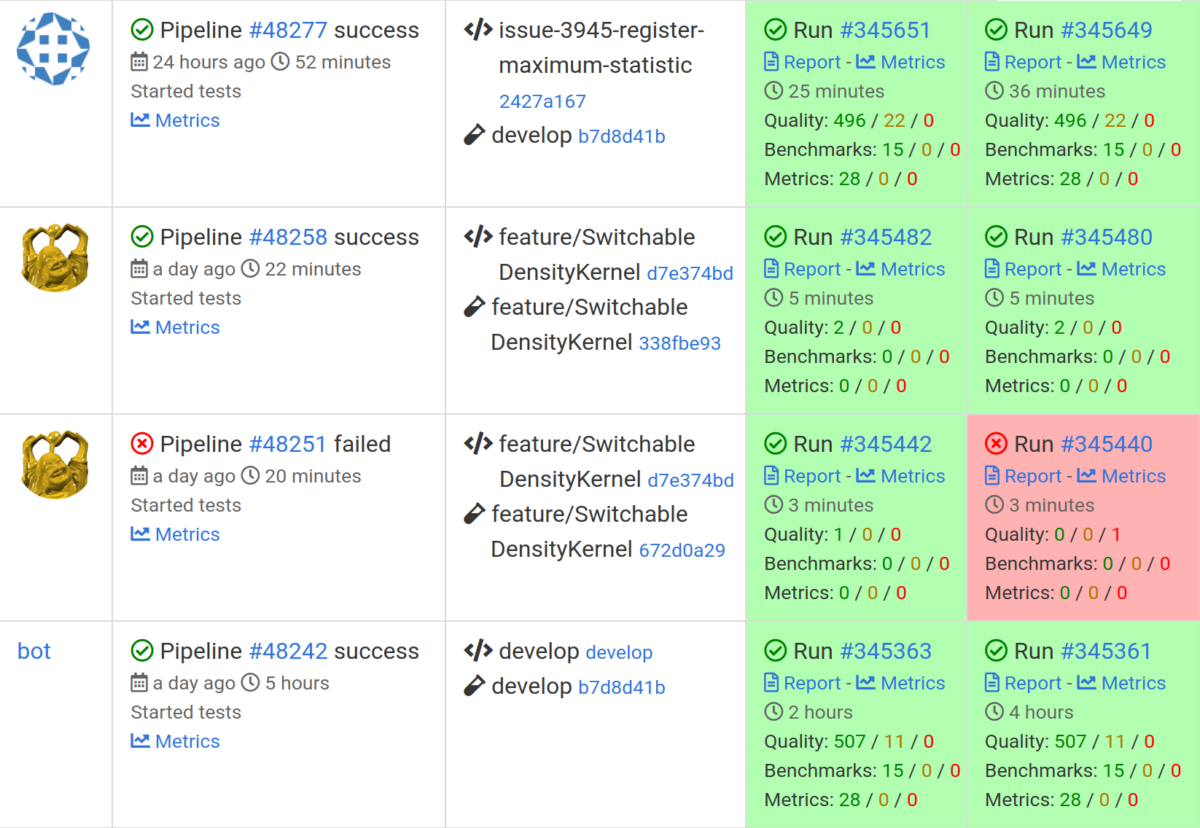
At FIFTY2, we have different stages where different variants of software testing is strictly incorporated in the development process. Like this, we minimize the risk of regressions and side effects and ensure reliable simulation results. It is always our goal to ensure, that the PreonLab version deployed to our users is the best version so far.